Common Questions about the NOrmal Distribution
Introduction
In this article, various questions regarding the normal distribution are answered. The effects of the mean and the standard deviation on the shape of the normal distribution are analysed. We will describe how to obtain probabilities of intervals and on the other hand how to construct confidence intervals for a certain level of confidence. The 1-tailed and 2-tailed  -scores are defined and we show how any normal distribution could be transformed into a standard normal distribution.
-scores are defined and we show how any normal distribution could be transformed into a standard normal distribution.
What determines the shape of the normal distribution?
The shape of the normal distribution resembles that of a bell. It is perfectly symmetric and is described completely by two parameters:  the mean and
the mean and  the variance. Equivalently, instead of the variance , one could use the standard deviation
the variance. Equivalently, instead of the variance , one could use the standard deviation  as the parameter that describes the normal distribution. The standard deviation is simply the positive square root of the variance. Note that is always taken to be a positive number.
as the parameter that describes the normal distribution. The standard deviation is simply the positive square root of the variance. Note that is always taken to be a positive number.
The graph of the normal distribution reaches its peak at  . The graph decreases to 0 as
. The graph decreases to 0 as  . However it never reaches 0. In other words, the graph never touches the
. However it never reaches 0. In other words, the graph never touches the  -axis. On the other hand, the graph decreases to 0 as
-axis. On the other hand, the graph decreases to 0 as  . Again it never reaches 0. In other words, the -axis is said to be an asymptote to the graph. The following is a plot of the normal distribution with
. Again it never reaches 0. In other words, the -axis is said to be an asymptote to the graph. The following is a plot of the normal distribution with  and
and  . The graph reaches the peak at
. The graph reaches the peak at  .
.
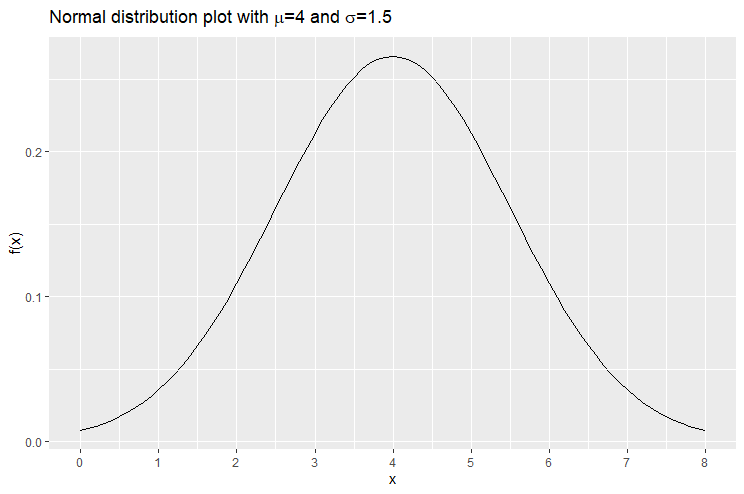
The following is the plot of the normal distribution with mean  and standard deviation
and standard deviation  . The normal distribution with these exact two values ( and ) is known specifically by the name: standard normal distribution. The standard normal distribution reaches its peak when
. The normal distribution with these exact two values ( and ) is known specifically by the name: standard normal distribution. The standard normal distribution reaches its peak when  and is symmetric about the -axis.
and is symmetric about the -axis.
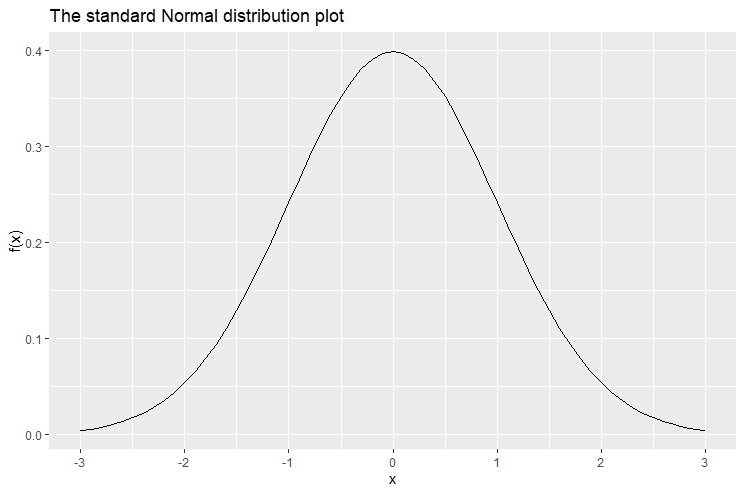
It is important to note that the curve of the normal distribution never cuts off. It continues indefinitely as and . Another intrinsic property of the normal distribution is that the area of under the curves is always equal to 1, no matter the choice of and .
What is the effect of the mean on the shape of the normal distribution?
As we already mentioned, the graph of the normal distribution reaches its peak at . Hence when we change the value of , we are changing the location where the graph reaches its peak. In other words, we are shifting the graph horizontally (along the -axis). The shape per se, is left intact with a change in the value of . The following is a plot of three different normal distributions. They all have their standard deviation equal to 1. However they have different values for the means. The red curve has mean -2, the green curve has mean 0 and the blue curve has mean 4.
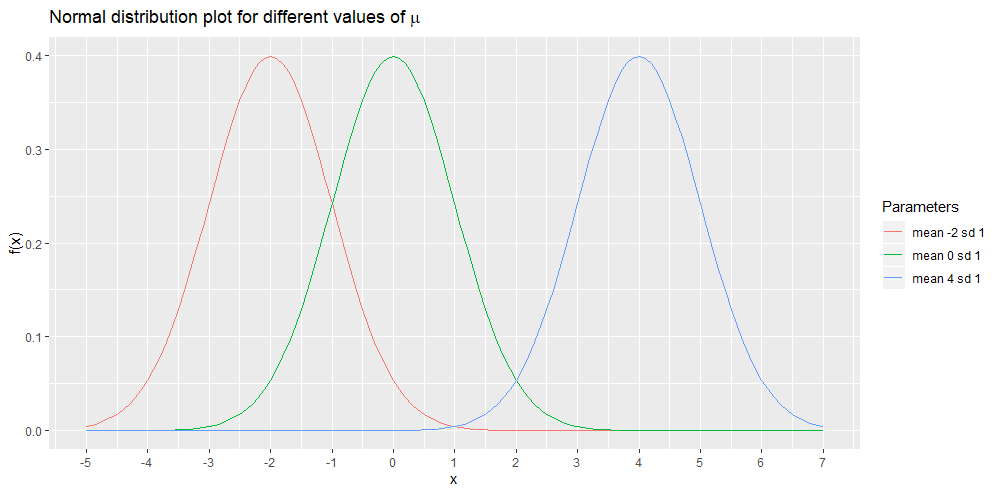
What is the effect of the standard deviation on the shape of the normal distribution?
In contrast to the mean, the standard deviation actually changes the shape of the distribution although the shape would always remain bell-like and symmetric. The next plot shows three normal distributions. They all have mean 0 but different values of . A small value of results is a graph that has a higher peak but more narrow tails (left-most and right-most parts of the curve). This fact is demonstrated by the red curve. A smaller value of results is a graph that has a higher peak but more narrow tails (left-most and right-most parts of the curve). This fact is shown by the red curve. A higher value of results is a graph that has a lower peak but wider tails. This is demonstrated by the blue curve.
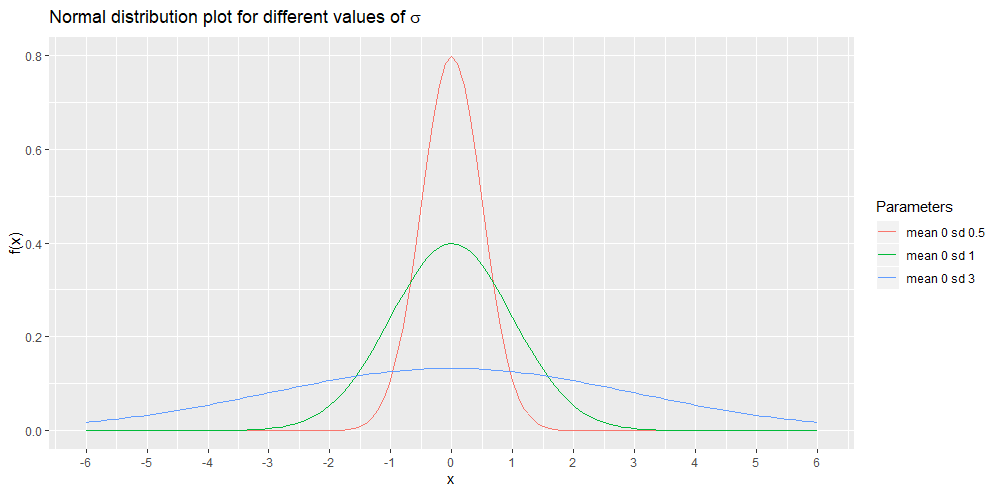
What does it mean that a random variable is normally distributed?
Suppose you have a random variable. This is a variable that takes on a particular real number in a random fashion according to some probability distribution. A well- known probability distribution is the uniform distribution. If, for example, a random variable follows a uniform distribution on the interval [0,1], it means that  can take on a value between 0 and 1, and each number between 0 and 1, has the same probability (chance) of being selected (hence the name uniform distribution).
can take on a value between 0 and 1, and each number between 0 and 1, has the same probability (chance) of being selected (hence the name uniform distribution).
Now, a normally-distributed random variable is a random variable which takes on values depending on the normal distribution. Since is a real number and thus can theoretically take any number from  to
to  , the probability is defined on intervals rather than points. The probability that takes a value between
, the probability is defined on intervals rather than points. The probability that takes a value between  and
and  is equal to the area under the curve between
is equal to the area under the curve between  and
and  .
.
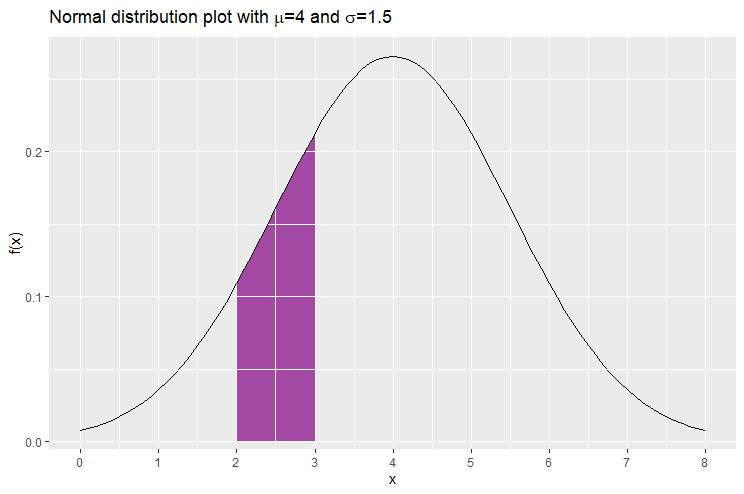
Consider for example a random number that follows the normal distribution with and . Suppose that we would like to find the probability that takes on a value between 2 and 3.
Let us plot again the graph of the normal distribution with mean 4 and standard deviation 1.5. We would like to find the area enclosed by the normal distribution, the -axis and the vertical lines  and
and  . This is the area shaded in purple below and gives us the probability that lies between 2 and 3. The area is 0.161, hence we write
. This is the area shaded in purple below and gives us the probability that lies between 2 and 3. The area is 0.161, hence we write ![\mathbb{P}[2\leq X \leq 3]= 16.1\%](https://datasciencegenie.com/wp-content/ql-cache/quicklatex.com-31c2247dafd8814f6dafb7ce85134213_l3.png "Rendered by QuickLaTeX.com")
Why is the mean called a measure of location?
The mean gives an idea of where the realisation of is expected to be. If, for example, we have a normally-distributed random variable with mean  , we expect that it will take some value around 4 for most of the time.
, we expect that it will take some value around 4 for most of the time.
Due to the symmetric bell-shape of the distribution, the mean of the normal distribution is equal to the median (since it is symmetric) and the mode (since it reaches the peak at ).
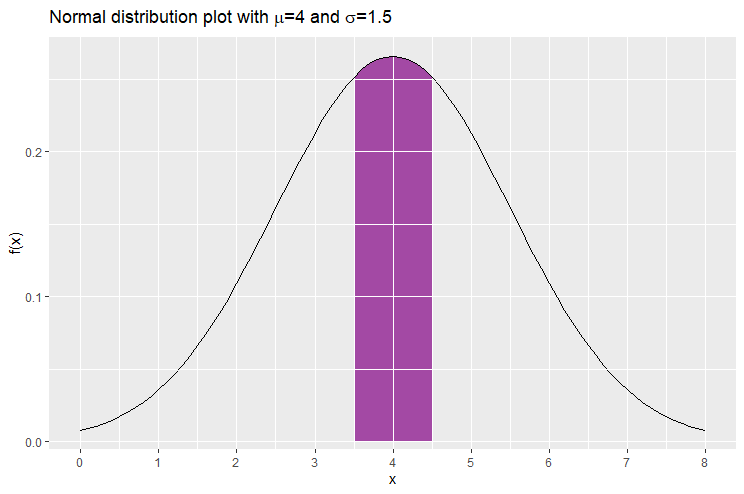
Moreover if you consider all the interval of same length, say  , the interval which has the highest probability of containing the value of is
, the interval which has the highest probability of containing the value of is ![[\mu-\frac{k}{2},\mu+\frac{k}{2}]](https://datasciencegenie.com/wp-content/ql-cache/quicklatex.com-68afa5b4725a2d41336cd3fc51804257_l3.png "Rendered by QuickLaTeX.com") . For example if is again normally-distributed with mean 4 and standard deviation 1.5, and we let to be 1, the interval of length 1 carrying the largest probability is [3.5,4.5], where
. For example if is again normally-distributed with mean 4 and standard deviation 1.5, and we let to be 1, the interval of length 1 carrying the largest probability is [3.5,4.5], where ![\mathbb{P}[3.5\leq X \leq 4.5]= 26.1\%](https://datasciencegenie.com/wp-content/ql-cache/quicklatex.com-3d0dc6a2ab344fc3451b6209c7727232_l3.png "Rendered by QuickLaTeX.com") . This associated area is displayed in purple below.
. This associated area is displayed in purple below.
Which are the most common -scores?
A random variable that follows the standard normal distribution is commonly denoted by the letter  instead of . This is just an issue of notation. Hence let us consider the random variable that follows the standard normal distribution.
instead of . This is just an issue of notation. Hence let us consider the random variable that follows the standard normal distribution.
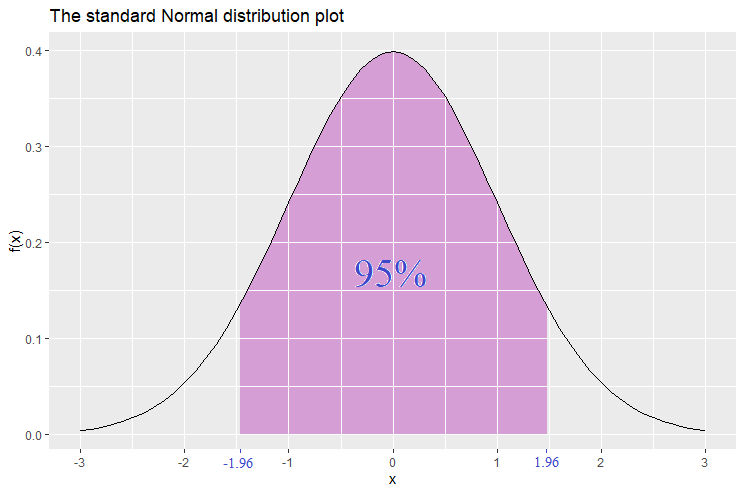
Suppose that we want to find an interval around the mean 0 (that is, is the center of the interval) that has a probability of 95%. The interval is found to be [-1.96,1.96]. Hence ![\mathbb{P}[-1.96\leq Z\leq 1.96]=95\%](https://datasciencegenie.com/wp-content/ql-cache/quicklatex.com-20342d41bf14e462c93b4a528179303f_l3.png "Rendered by QuickLaTeX.com") . Hence we are 95% confident that takes on a value between -1.96 and 1.96. The values -1.96 and 1.96 are called the 2-tailed 95% confidence level -scores. We call them 2-tailed because the shaded area in the graph below is concentrated in the middle part, and this leaves the two tails unshaded.
. Hence we are 95% confident that takes on a value between -1.96 and 1.96. The values -1.96 and 1.96 are called the 2-tailed 95% confidence level -scores. We call them 2-tailed because the shaded area in the graph below is concentrated in the middle part, and this leaves the two tails unshaded.
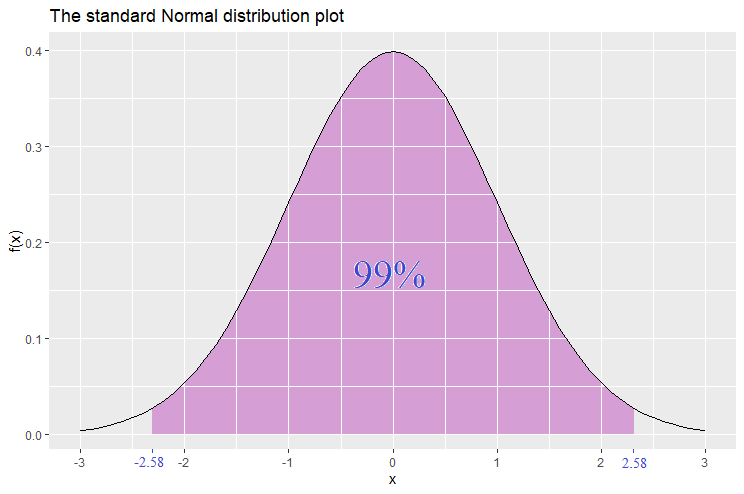
Similarly, let’s find the interval around the mean that carries a probability of 99%. This is found to be [-2.58,2.58]. Hence ![\mathbb{P}[-2.58\leq Z\leq 2.58]=99\%](https://datasciencegenie.com/wp-content/ql-cache/quicklatex.com-f1f7aef3cf543eac6e625d8380de6088_l3.png "Rendered by QuickLaTeX.com") . The values -2.58 and 2.58 are called the 2-tailed 99% confidence level -scores.
. The values -2.58 and 2.58 are called the 2-tailed 99% confidence level -scores.
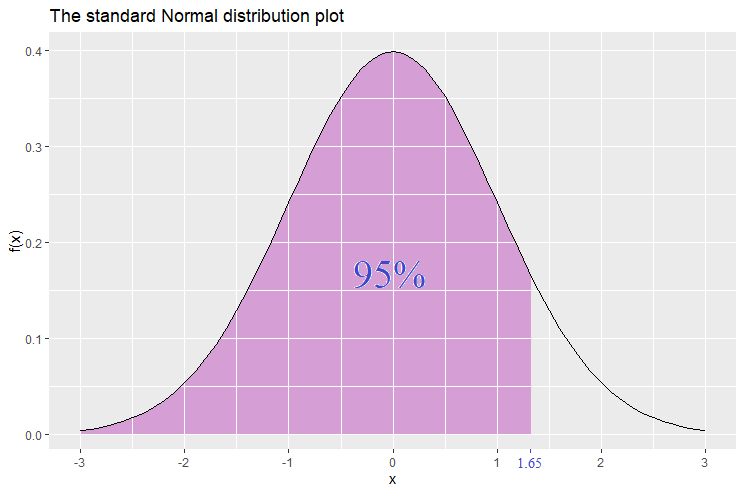
On the other hand there are also the 1-tailed -scores related to the 95% and 99% confidence level. Let’s start with the 95% confidence level. The shaded area starts from the left and only the right tail is unshaded. The area of the shaded part is 95%. The -value where the shaded part stops is 1.65. Hence we have found that the probability that takes a value less than (or equal) to 1.65 is 95%, that is, ![\mathbb{P}[Z\leq 1.65]=95%](https://datasciencegenie.com/wp-content/ql-cache/quicklatex.com-3d9316383d6393dba542dd296de802af_l3.png "Rendered by QuickLaTeX.com") . The value 1.65 is called the 1-tailed 95% confidence level -score.
. The value 1.65 is called the 1-tailed 95% confidence level -score.
Similarly, the 1-tailed 99% confidence level -score is 2.33. Hence ![\mathbb{P}[Z\leq 2.33]=99%](https://datasciencegenie.com/wp-content/ql-cache/quicklatex.com-71cf01f7da1b4aedb6a060f0c966498d_l3.png "Rendered by QuickLaTeX.com") .
.
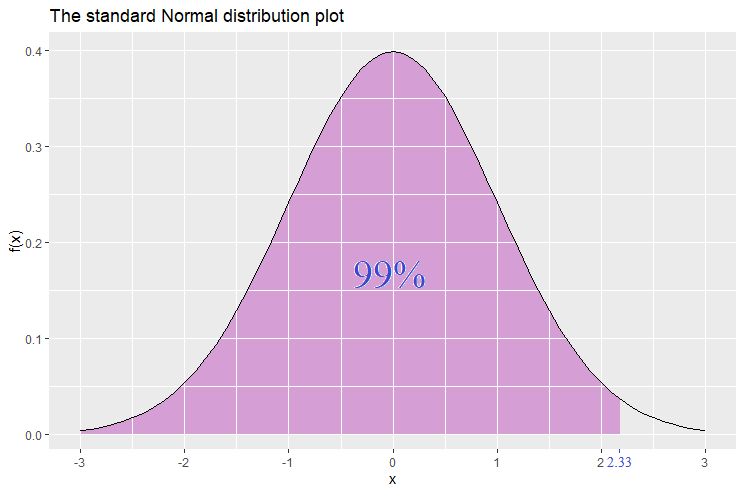
Since the normal distribution is symmetric, it follows that ![\mathbb{P}[Z\geq -2.33]=99\%](https://datasciencegenie.com/wp-content/ql-cache/quicklatex.com-05850b90b08b7176bbf2a253c569bc7b_l3.png "Rendered by QuickLaTeX.com") and this could be demonstated by a plot in which the shaded part starts from the right side and leaves the left tail unshaded.
and this could be demonstated by a plot in which the shaded part starts from the right side and leaves the left tail unshaded.
How are the -scores extended to be used for any normal distribution?
Consider the 2-tailed -scores. We have found that
![\begin{equation*} \mathbb{P}[-z\leq Z\leq z]=\alpha, \end{equation*}](https://datasciencegenie.com/wp-content/ql-cache/quicklatex.com-1415d97ef361897675778d4eb6a81bce_l3.png "Rendered by QuickLaTeX.com")
where  is the associated level of confidence (the probability of the interval). Every normal distributed random variable can be transformed into a standard normal distribution, through the equation:
is the associated level of confidence (the probability of the interval). Every normal distributed random variable can be transformed into a standard normal distribution, through the equation:

Hence:
![\begin{equation*} \begin{split} \mathbb{P}[-z\leq Z\leq z]&=\alpha\\ \mathbb{P}[-z\leq \frac{X-\mu}{\sigma} \leq z]&=\alpha\\ \mathbb{P}[\mu-z\sigma\leq X \leq \mu+z\sigma]&=\alpha \end{split} \end{equation*}](https://datasciencegenie.com/wp-content/ql-cache/quicklatex.com-84970fbba1fd0af9b8a6139b79fcfce1_l3.png "Rendered by QuickLaTeX.com")
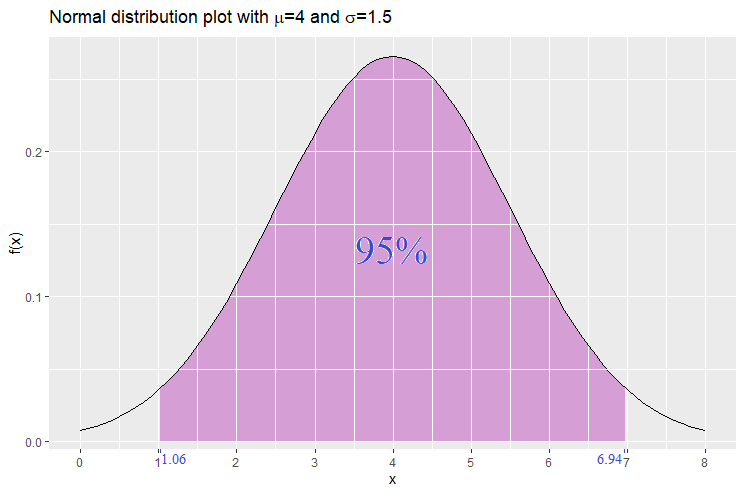
For example, let be normally distributed with mean 4 and standard deviation 1.5. Suppose that we would like to find the interval that carries a probability of 95%. We will thus make use of the 2-tail 95% -scores (-1.96 and 1.96).
![\begin{equation*} \begin{split} \mathbb{P}[\mu-z\sigma\leq X \leq \mu+z\sigma]&=\alpha\\ \mathbb{P}[4-1.96(1.5)\leq X \leq 4+1.96(1.5)]&=95\%\\ \mathbb{P}[1.06\leq X \leq 6.94]&=95\% \end{split} \end{equation*}](https://datasciencegenie.com/wp-content/ql-cache/quicklatex.com-d3df470ac1494a499ea3f181c2125b11_l3.png "Rendered by QuickLaTeX.com")
Hence the interval we expect that takes on a value between 1.06 and 6.94 with probability 95%. The plot below displays this result.
What is the 68-95-99.7 rule?
Let be a normally-distributed random variable with mean and standard deviation . If we had to find out the intervals which have probability roughly equal to 68%, 95% and 99.7% we obtain:
![\begin{equation*} \begin{split} \mathbb{P}[\mu-\sigma\leq X \leq\mu+\sigma]&\simeq 68\%\\ \mathbb{P}[\mu-2\sigma\leq X \leq \mu+2\sigma]&\simeq 95\%\\ \mathbb{P}[\mu-3\sigma\leq X \leq \mu+3\sigma]&\simeq 99.7\% \end{split} \end{equation*}](https://datasciencegenie.com/wp-content/ql-cache/quicklatex.com-d36a3e4d9bd8682f937117ab816f02ec_l3.png "Rendered by QuickLaTeX.com")
Thus with probability 68%, the realisation of is within 1 standard deviation away from the mean. With probability 95%, the realisation of is within 2 standard deviations away from the mean, and so on.
Why is the standard deviation called a measure of spread/dispersion?
The standard deviation gives an idea of how much the random variable is expected to vary from the mean. If you take a sample of realisations of , their difference from the mean  is expected to be around . The standard deviation measure how much the data of is close or far (dispersed) from its mean.
is expected to be around . The standard deviation measure how much the data of is close or far (dispersed) from its mean.
Take two normally distributed random variables  and
and  that both have mean , but has standard deviation
that both have mean , but has standard deviation  and has standard deviation
and has standard deviation  where
where  . Then the interval around the mean having an associated probability has a shorter length for the random variable .
. Then the interval around the mean having an associated probability has a shorter length for the random variable .
For example let be normally distributed with mean 0 and standard deviation 0.5, and let be normally distributed with mean 0 and standard deviation 3. Let  . Then we obtain:
. Then we obtain:

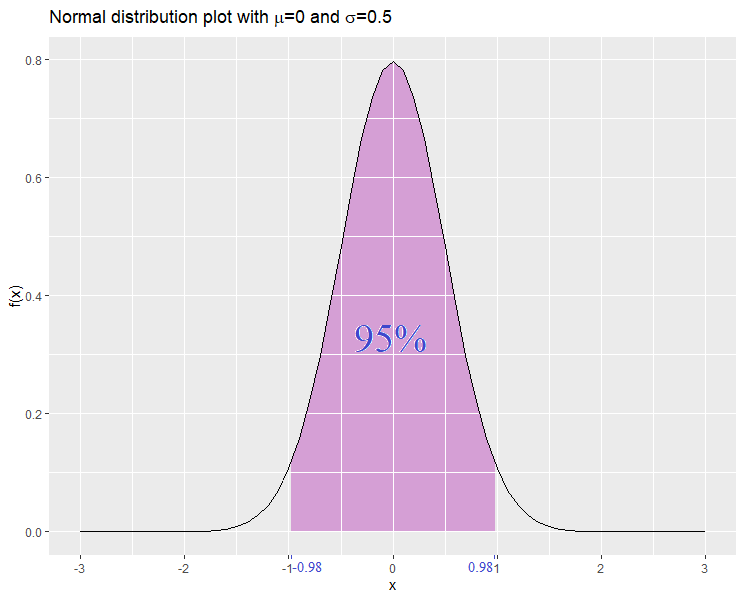
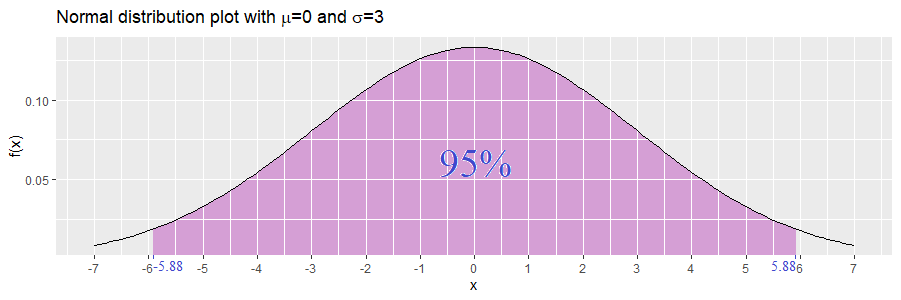
Since the interval for is shorter, then we have a clearer picture of which values are more likely to occur. This results from the fact that has a smaller standard deviation than .
What is the equation of the graph of the normal distribution?
The equation of the normal distribution is given by:

When entering various values for and one would obtain different plots of the normal distribution as described above. The computations done to find the probabilities of interval, are carried out by finding the area under the graph through integration. Nowadays, statistical packages, like Excel and R, could work out these probabilities, and -values or -values very quickly through in-built functions.